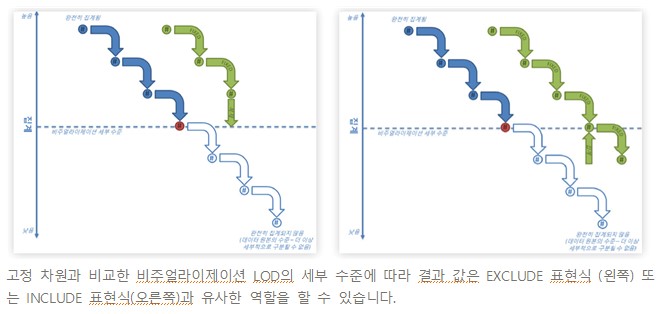
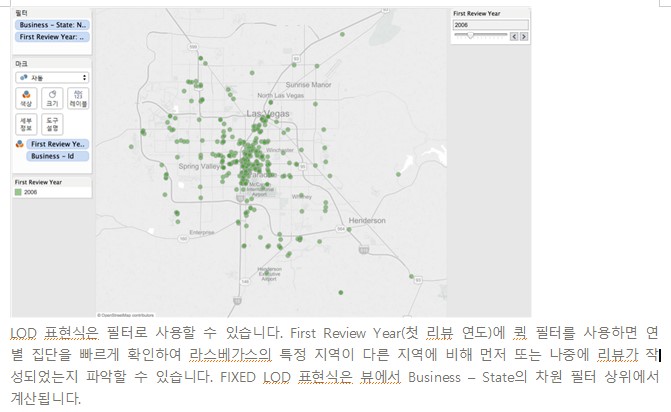
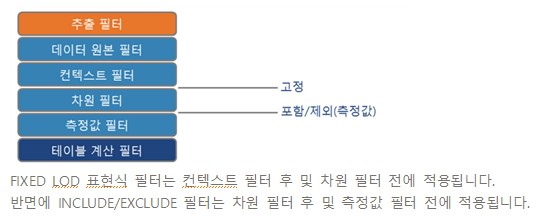
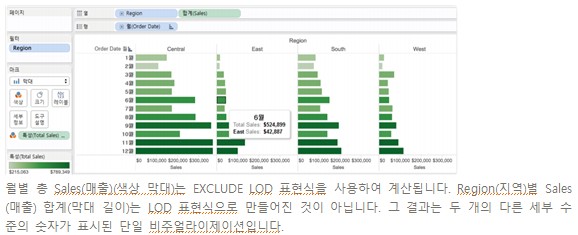
Tableau Data Management add on
Tableau Server 기반으로 작동하며 추가 라이선스 활성화 후 사용할 수 있습니다.
Tableau Data management add-on은 다음 제품을 포함합니다
Tableau prep conductor
Tableau catalog
Tableau 데이터 관리를 사용하면 분석 환경 내에서 데이터를 더 잘 관리할 수 있으므로 항상 신뢰할 수 있는 최신 데이터를 사용하여 의사 결정을 내릴 수 있습니다. 데이터 준비에서 카탈로그 작성, 검색 및 거버넌스에 이르기까지 Tableau Data Management는 데이터에 대한 신뢰를 높여 셀프 서비스 분석의 채택을 가속화합니다.
Tableau Data management를 선택해야 하는 이유
- 모두를 위한 신뢰
IT에서 개별 분석가에 이르기까지 Tableau Data Management는 데이터 환경에 대한 신뢰를 높이는 데 필요한 가시성과 제어 기능을 제공합니다.
- 올바른 데이터의 검색 가능성
Tableau 데이터 관리를 사용하면 모든 사람 이 분석에 올바른 데이터가 사용되고 있다고 확신할 수 있습니다.
- Tableau 플랫폼과 통합
Tableau를 위해 제작된 데이터 관리 옵션으로 데이터 및 분석 환경을 최대한 활용할 수 있습니다.
- 대규모 데이터 관리
데이터 관리를 운영하고 자동화하여 셀프 서비스 데이터 준비 및 분석을 보다 쉽게 수행할 수 있습니다.
Tableau Prep Conductor
자동화, 가시성, 모니터링
Prep Builder에서 사용자가 만드는 데이터 처리 흐름을 전사적으로 적용하고 운용할 수 있게 해주는 서비스로 개인 사용자가 만드는 데이터 변환을 전사 수준으로 확장시키며, 데이터 흐름 예약, 모니터링 및 관리에 유용합니다.
1. 서버에 흐름 게시 및 실행
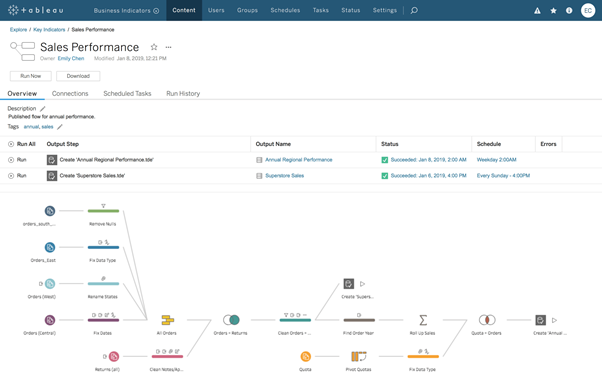
- Tableau Prep Conductor를 사용하면 서버 환경에서 흐름을 쉽게 게시하고 실행할 수 있습니다. Tableau Server 또는 Tableau Online을 사용하여 데이터 원본을 안전하게 공유하십시오. 조직의 모든 사람이 준비된 최신 데이터로 작업할 수 있는 환경을 만듭니다.
2. 흐름 스케쥴링
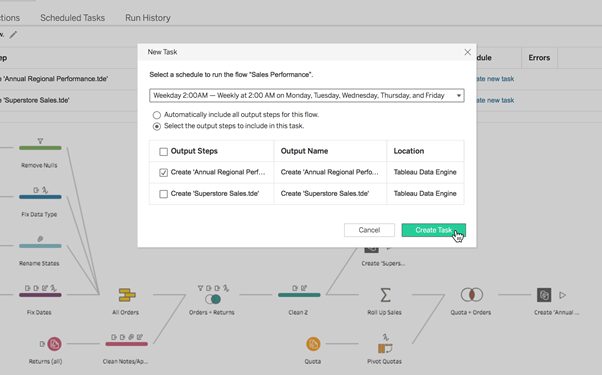
- 낮이나 밤에 필요할 때 흐름이 실행되도록 예약하세요. 데이터 준비 프로세스를 자동화하여 항상 최신 데이터를 준비하고 분석할 수 있도록 합니다.
3. 서버 전체의 흐름 모니터링

- 현재 Tableau Server에서 사용할 수 있는 동일한 도구로 흐름을 모니터링하십시오. 상태 페이지, 관리자 보기 및 실행 기록을 사용하여 전체 서버의 흐름 상태를 확인하여 문제를 신속하게 해결할 수 있습니다. 사전 경고로 흐름이 정상인지 항상 확인하십시오.
Tableau Catalog
Tableau 환경의 모든 데이터에 대한 이해가 가능하며 손쉽게 데이터 계보를 확인하고 영향도 파악을 할 수 있습니다. 또한, 신뢰 가능한 데이터 확인 후 Tableau 서버에 통합하고 Metadata API를 통해 타 시스템과 연계 가능합니다.
1. 가시성, 신뢰, 검색 가능성.

Tableau Catalog는 모든 사람에게 혜택을 줍니다. Tableau Catalog는 데이터에 대한 완전한 그림과 Tableau 환경의 분석에 연결되는 방식을 제공함으로써 IT 및 비즈니스 사용자 모두의 신뢰와 검색 가능성을 높입니다. 데이터 변경 내용을 전달하거나 대시보드를 검토하거나 분석에 적합한 데이터를 검색하는 경우 Tableau Catalog를 사용하면 조직에서 항상 올바른 데이터를 사용하고 있다는 확신을 가질 수 있습니다. 더 나은 가시성은 더 나은 데이터 관리를 의미합니다
2. 데이터에 대한 전체 보기
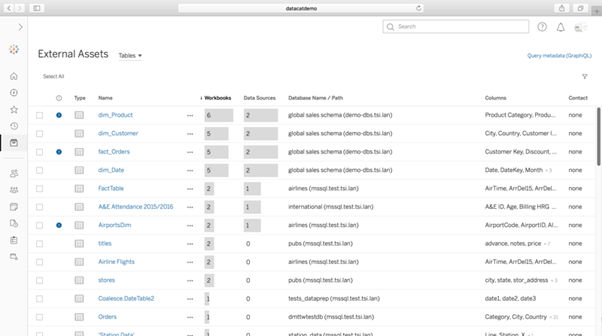
Tableau Catalog는 Tableau 환경의 모든 데이터 자산을 하나의 중앙 목록으로 자동으로 수집합니다. 인덱스 일정을 설정하거나 연결을 구성할 필요가 없습니다. 한 곳에서 모든 테이블, 파일 및 데이터베이스를 빠르게 볼 수 있습니다.
3. 데이터 관계를 더 잘 이해
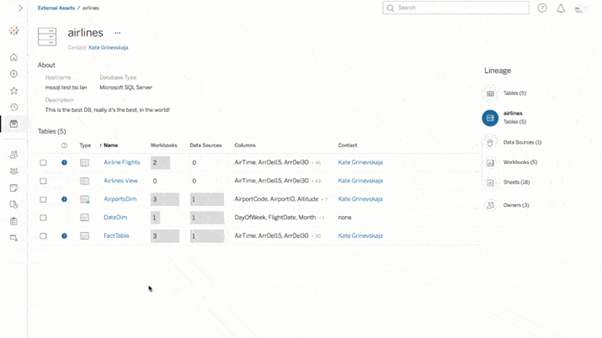
- 데이터베이스 마이그레이션, 필드 사용 중단 또는 테이블에 새 열 추가는 모두 환경의 자산에 잠재적인 영향을 미칩니다. 계보 및 영향 분석을 사용하면 어떤 자산이 업스트림 및 다운스트림에 영향을 미칠지 뿐만 아니라 영향을 받는 사람도 확인할 수 있어 모든 사람의 골칫거리를 최소화할 수 있습니다.
4. 컨텍스트의 메타데이터

- 데이터 세부 정보는 대시보드만 보고 있는 사용자도 분석 중인 데이터를 신뢰할 수 있도록 합니다. 데이터 품질 경고를 사용하여 한 곳에서 상태를 설정하고 데이터 소스에서 대시보드에 이르기까지 환경 전체의 모든 자산이 사용자에게 관련 정보를 제공하여 자신 있게 비즈니스 결정을 내릴 수 있도록 합니다.
5. 분석에 적합한 데이터 찾기

- 분석을 시작할 데이터를 아는 것은 어려울 수 있습니다. 데이터에 연결할 때 더 많은 메타데이터와 컨텍스트를 사용할 수 있으므로 분석에 적합한 데이터를 사용하고 있으므로 안심하십시오.
6. 조직 전체에서 메타데이터 활용
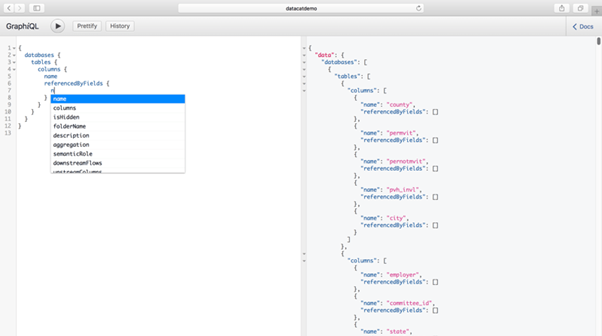
- 메타데이터는 조직 전체의 여러 애플리케이션에 존재합니다. Metadata 및 REST API를 사용하여 분석이 수행되는 Tableau에서 메타데이터를 가져옵니다.
Tableau는 현대적인 셀프 서비스 분석을 통해 비즈니스 인텔리전스 환경을 혁신했습니다. 도메인 전문 지식을 가진 사람들이 직관적이고 시각적인 분석을 할 수 있다는 것은 사람들이 IT에 의존할 필요 없이 자신의 데이터 질문을 탐색하기 시작하고 분석을 쉽게 반복하여 새로운 통찰력을 발견할 수 있다는 것을 의미합니다. 이제 최신 분석 배포가 증가함에 따라 IT는 올바른 데이터를 선별, 관리 및 홍보해야 하는 문제에 직면하고 있으며 비즈니스 사용자는 분석을 위해 관련성이 있고 신뢰할 수 있는 데이터를 찾는 데 어려움을 겪고 있습니다.
사람들이 데이터를 보고 이해할 수 있도록 지원하기 위해 Tableau는 고유한 방식으로 사용자를 위한 데이터 관리에 투자하고 있습니다. 분석의 맥락에서 사용자에게 도달하는 고도의 시각적 솔루션을 통해 조직의 모든 사람이 올바른 데이터를 가지고 있으며 의사 결정을 위해 신뢰할 수 있음을 알 수 있도록 돕고 있습니다. 가시성, 검색 가능성 및 신뢰를 높이면 관리되는 데이터 환경을 확장하는 데 도움이 됩니다. 즉, IT 부서는 급증하는 데이터 소스와 분석 콘텐츠를 더 잘 관리할 수 있고 최종 사용자는 원하는 데이터를 더 빨리 찾고 분석에 자신감을 가질 수 있습니다.
Tableau data management add-on 을 체험하시려면 아래 링크를 클릭해주세요
https://10az.online.tableau.com/#/site/demodepot/catalog/tables
'자료실 > Tableau' 카테고리의 다른 글
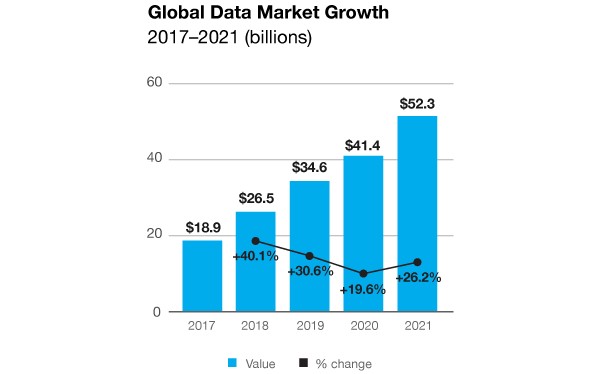
| 국내외 데이터 산업의 시장 규모는 얼마나 될까요? (0) | 2021.09.02 |
|---|---|
| 다양한 태블로 차트 (14. TabPy 분석 확장 프로그램) (0) | 2021.06.04 |
| 다양한 태블로 차트 (13. 블렌딩&와플차트) (0) | 2021.06.04 |
| 다양한 태블로 차트 (12. 사용자 지정색상, 모양) (0) | 2021.06.04 |
| 다양한 태블로 차트 (11. 라인 매트릭스) (0) | 2021.06.04 |